IM项目中的消息推送设计
在实时通讯系统中,消息的发送和接收是最重要的部分,要实现高效稳定的消息系统,需要考虑多个关键点,比如保证消息的时序性、消息可靠ACK、避免消息重复、热点群扩散风暴等。
在下图中,我们考虑了几个重要的方面,并对相关场景进行模拟,给出初步的解决方案。
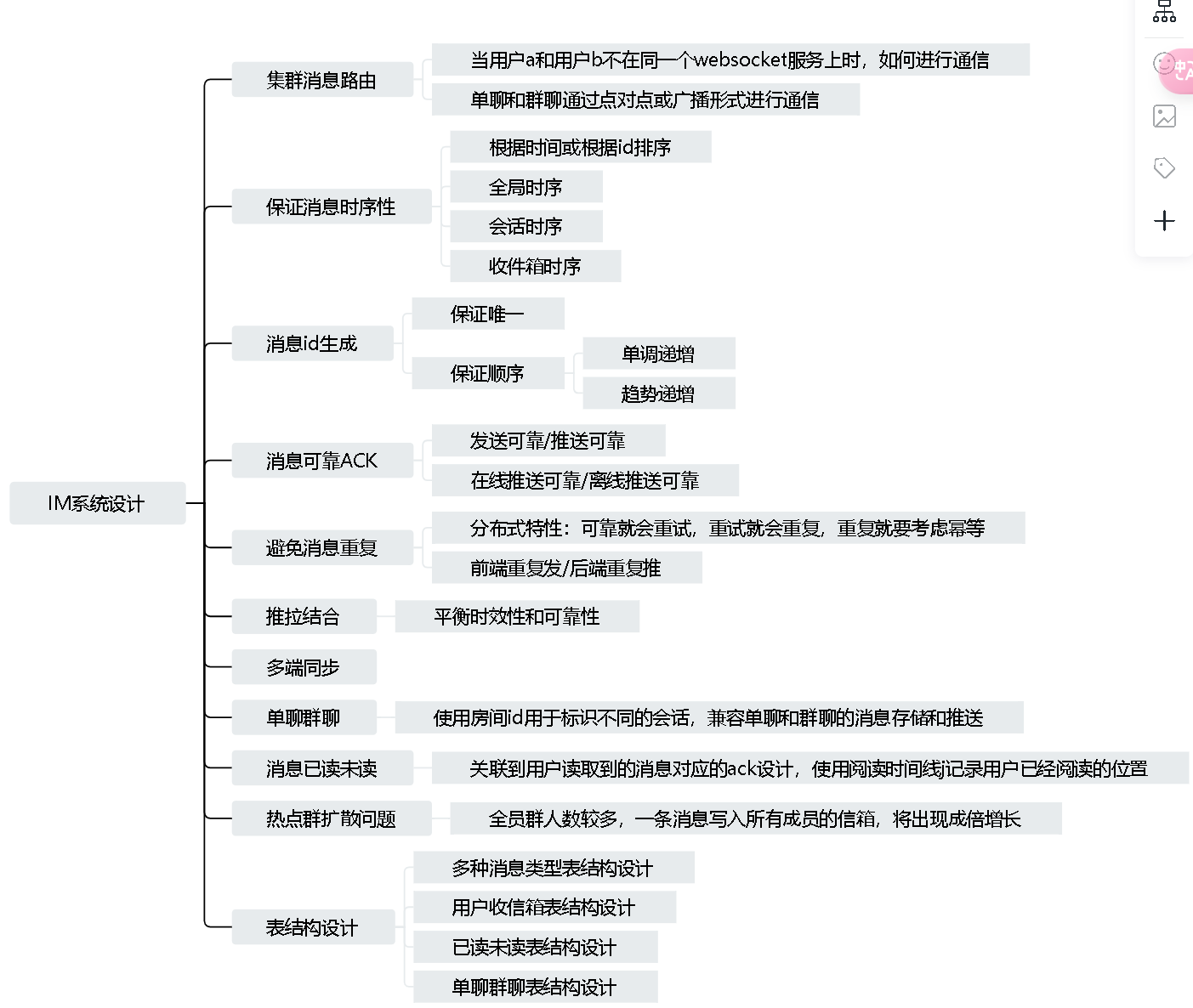
对于一个千万级的消息系统,任何一个小功能,都可能成为性能瓶颈,都需要复杂的设计去支撑。在我们的项目中,由于是web项目,在一些细节实现方面和客户端IM有所不同。下图为具体的流程实现:
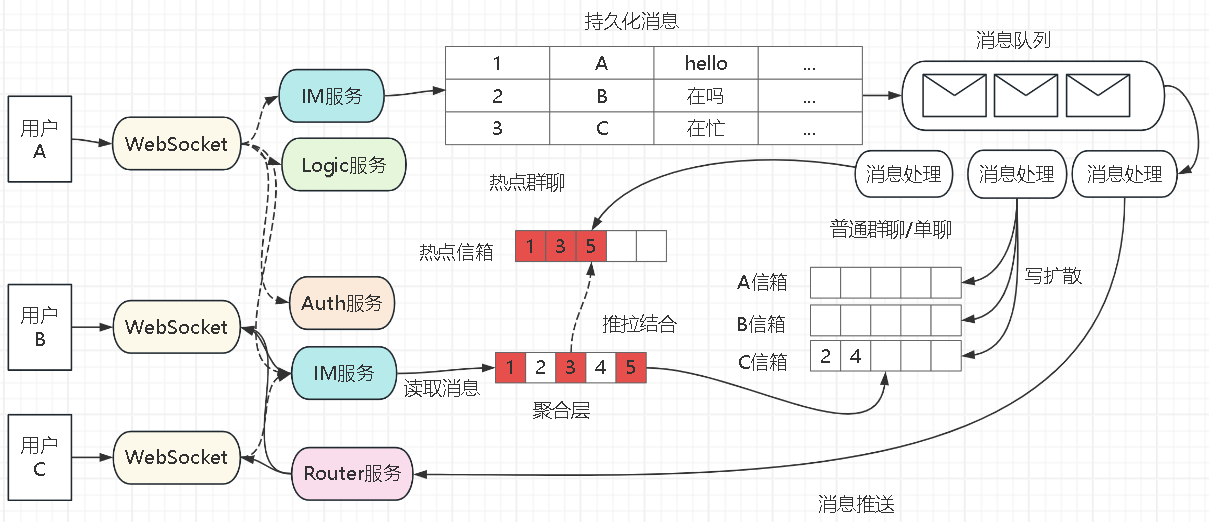
其中,各个服务的功能如下:
1)Websocket:用于维护和用户连接的通道,可以接收消息,也可以推送消息,是有状态服务。
2)IM服务:负责消息的发送逻辑,处理单聊群聊的消息。
3)Logic服务:负责处理用户的心跳检测,上下线通知,联系人添加查看,创建群组等逻辑。
4)Auth服务:处理用户认证,权限等需求。
5)Router:推送消息时,不同用户在不同websocket上,需要确保正确推送和可靠推送。
交互的流程大致如下:
1)用户a和WebSocket服务建立连接,之后都通过该连接发送消息,接收消息。
2)用户a在群组中发送一条群消息”在吗“,WebSocket服务将消息通过IM服务实现消息发送。
3)IM服务使用本地消息表将消息进行持久化,然后将消息通过RocketMQ进行投递,并在前端进行快速响应,mq的消费者根据负载慢慢进行后续的推送,写扩散等操作。
4)其中消费者根据当前消息是否为热点群聊的消息实现不同的逻辑,如果是热点群聊,只写热点信箱,如果是单聊或者普通群聊,会写扩散到每个群成员信箱,比如发送的消息在包含用户b和c的小群时,会将该消息写入用户b和c的信箱。
5)将消息投递到信箱后,需要将消息推送给用户,这里可以根据用户是否在线选择不同的推送方式,如果用户在线,则使用WebSocket进行推送,如果用户离线,进行push通知。由于不同的用户连接在不同的WebSocket上,因此需要Router服务将消息推送到不同的WebSocket上。
6)推送的时候需要确保消息的可靠性,如何确保消息一定推送成功?可能需要做应用层的ack确认,类似于tcp的滑动窗口确认。
7)用户在查询自己的会话列表时,需要有一个消息聚合层来聚合用户信箱以及热点信箱,经过严格的时间和群组排序后返回给用户,也就是推拉结合。
集群推送
我们使用WebSocket进行消息推送,因为http是无状态的,每次请求都会重新握手建立tcp连接再发送消息,并获取响应。因此http请求可以随意进行负载均衡,比如第一次请求发到机器a,第二次请求发到机器b,都能正常响应。
而webSocket是有状态的,当建立tcp连接后,就会一直复用这个连接进行通信,直到连接断开,重新连接后才会更换连接。
在我们的项目中,使用netty来实现WebSocket,和用户的连接就是一个Channel,需要给用户推送消息时,直接往channel中write消息即可。
1)方案1:缓存用户uid和channel映射
在用户登录的时候,通过将uid和用户对应的channel关联起来缓存到jvm的map中,在需要消息推送的时候只需要通过当前用户uid取出对应的channel即可进行推送。
如果使用多台机器进行推送时,当要推送的用户在别的服务器上,如果不进行中心化存储时就无法获取到对应的channel,因为连接的管理都是在jvm层面,不同的服务器上所存储的channel是不同的。此时有一种思路就是使用Redis对所有服务器的uid和channel的映射关系进行存储,通过要发送消息的目标用户uid获取对应的channel,但是由于channel是服务器本地的socket连接,就算中心化了,也无法进行存储和反序列化。
可以对上面的方案进行优化一下
2)方案2:方案1+redis维护用户连接状态
本地依然维护uid和channel的关系,redis另外再维护用户的连接状态,比如用户连接在哪个服务器上,这样通过router进行消息发送的时候就知道用户的消息应该发往哪台机器。
大概的流程如下:
- A发送了一条给C的消息。通过
channel发送给了10.102.1.1这台websocket,它通过dubbo将消息随意转发给了一台IM服务。 IM服务将消息持久化后,调用Router,推送消息给CRouter查redis的中心化管理,查到C目前连接在10.102.1.2上,并通过tcp连接将C的消息推送给10.102.1.2。Router会和所有websocket都维护一条tcp连接。查到具体的ip后,对指定websocket服务器进行消息推送。websocket服务收到的请求格式为给uid发送xx消息,所以它会通过uid在本地的连接管理中,查出用户具体的channel。然后调用channel.write(消息)方法,给用户推送消息。
但是这种方法
1)需要频繁更新redis去维护用户和websocket服务的映射,当然在做用户的上下线时也会复用到。
2)更主要的问题是连接数爆炸,因为如果用户一多,就需要水平扩容websocket和router。
3)虽然实现复杂,但需要指定ip推送,维护tcp连接。如果用dubbo会稍微简单些。
4)消息发送开销:对于群聊,多个接收者需要发送多份消息的副本,增加了消息发送的开销(这个对比后面的方案就能理解)
5)延迟叠加:哪怕开启了多线程,也依然会有一台机器的单点,需要对所有的群成员进行消息的扇出(写扩散)。这里会导致接收者接到的消息延迟叠加。(当然,用线程池异步扇出可以提高速度,但是会回到问题4,总体开销依然是不变的)
6)雪崩问题:如果系统负载提高,比如需要推送的消息量突然变大,导致瓶颈从websocket一直传导到router再传到im服务,整个集群会出现雪崩,需要有一个消息队列来进行削峰填谷。
其中router是为了让你能够精准投递的重要功能。
他可以是一个服务,这样你的消息只需要发送到任意一个router上,他就能帮你转发到对应的websocket。
他也可以是一个SDK,这样减少一次服务与Router服务的交互,简短链路。SDK提供的能力就是根据接收人UID,去redis查到UID所在位置,直接精准请求到Websocket服务。
3)集群广播消息
这种方法无需维护连接,消息的发送只需要一个消息副本,并且没有消息扇出的压力,而且只需要写一次。
对于万人群聊,一般系统的压力在于消息的扇出(写扩散),如果按照精准投递的话,我们的消息需要查询redis中心路由,然后将消息重复发送1w次。而如果使用消息广播的形式,消息只需要投递一次,由websocket自己进行广播消息的拉取和过滤。
1)此时mq的消费模式为集群消费,确保每台websocket都能消费到所有需要投递的消息。
2)只需要对比要推送消息的uid在不在本地连接管理的列表中,如果不在,直接丢弃消息,也就是过滤消息。
3)如果在本地连接管理,根据uid取出channel,就能进行消息推送。
优化1:消息副本优化
在万人群聊下,其实大家收到的消息都一样的,可以共用一个消息副本,我们在投递消息进mq的时候,可以设置投递的消息为list<long>的uids。而不是拆成多次的消息投递。这样就能够减少消息副本,对于大群聊下的优化效果更强。但是对于小群聊或者单聊的占比很大,群聊人数很少的情况,集群广播就失去了优势。
优化2:消息过滤优化
在刚刚的过滤流程中,消息内的uid过滤,都是在本地消费者逻辑中过滤的,不存在就直接丢弃消息,此时大量与本websocket无关的消息都被拉取过来,中间的网络io就浪费了,也浪费了本地反序列化的cpu。
解决思路有:
1)可以设置header的方式,将推送的uids存在header中,这样拉取消息到消费端的时候,就可以在序列化之前,先在mq的过滤器中过滤消息,节省不必要的反序列化。这里需要考虑到header有长度限制,需要注意大群聊的uid过多,需要分批发送,或者群聊不过滤,只考虑单聊场景。
这种方案的缺点是如果全站的消息都是单聊消息,结果每个websocket都会拉取消息,并且内部过滤,造成带宽和内存的浪费。
因此可以得出一个简单结论:单聊消息多的,使用精准投递。群聊消息多的,使用集群广播消息。
由于我们的项目中包含全员群,也有很多小群聊,有很多的单聊,发言频率最高的也是全员群,因此使用了集群广播消息推送方案。
保证消息时序性
主要是需要解决消息展示的顺序问题,比如用户a给用户b同时发送aa,bb,cc,由于服务端接收消息是并发的,可能入库就是aa,cc,bb,也就产生了发送方顺序和接收方顺序不一致的情况。
我们可以从两方面进行确保有序性。
1)客户端排序
可以让用户a发送的每条消息都带上时间戳,服务端存储用户a的消息时间戳,用户b根据时间戳进行排序展示。
对于每条消息,设置消息自增id,对于同一时间内的数据,通过消息自增id区分。但是这种方法在群聊场景下,每个群成员的客户端时间都不一样,无法作为排序的同一基准,而且不同客户端的消息自增id序号也不同,相同秒内无法排序,只能采用服务端时间。
2)服务端排序
对于单表来说,可以使用主键id来排序,也可以通过消息的时间戳来排序,由于主键id是严格递增,而时间戳需要考虑时间精度,一般设置为毫秒,基本足够用于消息的排序了,因为毫秒内的消息本身没有上下文关系,对顺序要求不高。
而除了消息的顺序性,还有消息的唯一性也需要保证。在游标翻页的场景下,翻页的游标字段需要同时保证顺序性和唯一性,因此单纯用时间戳的话无法对毫秒内的消息进行区分排序,还需要拼接其他字段,还不如直接使用唯一且有序的id作为游标。
消息id全局唯一且有序
消息id需要保证唯一且有序,可以使用分布式id保证唯一,重点是如何保证消息的有序。
1)全局递增
事实上,严格的单调递增,意味着严重的单点竞争问题,对一个需要分库分表的系统,很难实现这样的方案。
2)会话级别递增
对于多个群组消息,只需要保证单个群组中的消息id有序即可,简单的做法是分库分表以会话id分表,这样相同的会话必定在同一张表中,因此又可以用回主键id自增。
3)收件箱递增
会话级别递增,适用于读扩散的场景,所有人拉取消息列表时,都去会话的消息表拉取。
收件箱递增,适用于写扩散的场景,每个人都有自己的收件箱,维护自己的时间线即可。
收件箱的时间线的单调递增和用户uid相关,也就是是以uid为key进行排序。
消息可靠ACK
消息时序性和可靠性是IM产品最重要的功能,IM的消息发送一般分为两个场景
1)发送方发送消息给服务端,服务端入库成功返回ack。
2)服务端推送消息给接收方,接收方返回ack。
发送可靠ACK
确保发送的消息可靠,需要靠ack保证,但我们需要的是业务层的ack,而不是传输层的ack,也就是说不能借助tcp的ack。比如用户发送消息到服务器了,此时tcp的ack已经响应了,代表服务器收到了请求,但是服务器在入库的时候失败了,可能是在业务层出现了失败,比如业务校验,db入库,代码执行等,只有业务层返回的ack才算业务可靠的保证。
如果是通过websocket发出的消息,需要websocket再主动返回一个ack消息。因为websocket底层是tcp协议,特点是发消息和接收消息是没关系的,因此需要通过一个唯一标识,将推出去的消息标识为用来响应上一个接收的消息。同时发消息的客户端,也需要发送完进行阻塞等待,等待响应的到来。
推送可靠ACK
推送可靠一般体现在服务端消息入库成功后,推送给对应的消息接收方,需要保证消息能够准确到达接收方。
这里推送给每个人的消息对应的ack需要入库,也就是说可以写到本地消息表中进行持久化,当消息发送成功后,接收到ack,再修改消息的状态,表示发送成功。
1)定时重试:不一定每次发消息都能够成功,因此需要能够定时重试,将没有收到ack的消息进行重新推送。因此可靠的前提是消息信箱是持久化的,定时任务支持不断重试的。
但这也会出现一个问题,就是如果用户一直不在线,难道我们的定时任务需要一直拉取全部信箱消息,再判断用户是否在线进行推送吗?其中的拉取消耗是较大的。
2)在线推送:可以对推送服务增加一个判断,如果是用户在线,消息才进行推送,并记录消息在内存中,定时任务只会拉取内存ack队列的消息,进行推送重试。如果收到ack,内存队列会移除对应的待ack消息,并且对持久化的信箱进行ack标识,如果内存待ack队列过多,采用lru的方式,排除最早入队的消息。
当然内存队列肯定是不可靠的,只是为了加速可靠推送的效率,最终还有持久化信箱做兜底,最后的保障就算离线推送。
3)离线推送:对于不在线的用户,只能确保他在下一次连接上的时候,保证消息的可靠推送,在此之前,通过push的方式提示消息到达。
当用户上线时,需要查出他所有未ack的消息,然后全部推送给他,并且copy一份到内存ack队列,确保可靠性。后面的流程就和之前差不多,定时任务再继续重试,保证最终的一致性。
而一次性推送所有消息,可能会有瓶颈,可以通过分批推送实现优化。
使用本地消息表实现操作一致性
需要确保本地的操作和第三方操作保证一致,要么都成功,要么都失败。由于网络的不可靠性,会出现本地成功了,但是第三方可能网络波动,没有执行成功。事务消息保证的就是第三方一定要执行成功,达到最终一致性。
把对第三方的操作,都变成一条本地的记录和我们的本地事务一起入库。这样就保证了持久化,至少这个操作不会丢失了。
然后通过定时任务来保证这条操作一定会被执行成功,如果一次遇到网络波动,返回超时,没有关系。定时任务会一直查出来,最终返回一个确定的结果(成功或失败)。这时候就可以删除这条操作明细了。保证了最终一致性。
rocketmq需要发送的消息的topic,消息内容等。
分析发现,无论是任何对第三方的操作,对应的java代码中,不过都是执行一个方法而已。
那我们存的本地消息表,就可以高度抽象成对方法的执行,确保某个方法执行成功。
其中本地消息表保存当前事务的执行状态,请求快照参数json(也就是方法的全限定类名,以及入参,重放的参数),下一次重试的时间,已经重试的次数,最大重试次数,执行失败的堆栈,
在rocketmq的发送消息时,加入secureInvoke注解(保证能够执行成功,如果是在事务内的方法,会将操作记录入库,保证执行成功),保证事务提交后发送成功。
比如在controller中,调用了业务方法,然后调用了其他dao的方法,它会将rocketmq发送消息的方法存在本地消息表,之后回放的时候,再进行实际的业务逻辑调用。
这里主要是通过切面实现,对于不在事务内的方法,直接执行,不做保证,对于在事务内的,对需要执行的方法进行解析,解析成dto对象,其中包含类名和方法名以及入参类型,参数,使得在执行的时候能够正确调用对应的对象。然后再保存该方法对应的本地消息表记录。
为了加快事务中的方法执行成功,我们在事务结束后,就执行一次。通过在当前事务管理器中,定义一个钩子方法,在事务提交后,进行回调我们的消息记录,相当于直接执行了一次。这里执行分为同步和异步,异步调用线程池,同步就直接调用。
当我们从消息记录中取出一个记录时,也会先取出相应的快照信息,然后再执行对应的方法。
在同步执行情况下,需要对状态进行标识,可能当前事务对应的threadlocal还没有清除,导致事务状态判断不准确。
通过设置事务invoke状态下的上下文,用于判断当前是否是在事务内还是属于重试阶段。
避免消息重复
在分布式场景下为了达到最终一致性,失败后需要进行重试,重试就有幂等问题,需要表明两次重试是同一次操作,不能因为重试就插入两条数据。
发送消息幂等
消息发送时,如果遇到网络波动,底层会自动帮忙重试。如何唯一标识这条消息呢?靠发送端生成唯一的标识,如果重试的时候,相同的消息带的是相同的标识,后端就能够检测出来,保证幂等。
接收消息幂等
服务端对接收方的消息推送,也是有可靠性保证的。如果没有及时收到ack,定时任务就会进行消息推送重试。同样需要考虑到幂等问题。
假设服务端对接收方推送了相同的消息两次。接收方会怎么展示呢?一般能够想到对消息做幂等判断,如果是客户方已经展示的消息,就跳过。那么这个唯一性怎么判断呢?
消息的唯一性,基本就靠消息id来判断了。上面也讨论了消息id的唯一性问题。一般全局消息唯一的话。直接用唯一消息就好了。如果是会话级别的消息id唯一,那判断的时候就需要判断会话id+消息id唯一。
推拉结合
1)推模式
当有新消息时,服务端需要主动推送给前端,此时主要通过websocket实现,并且后台会维护一个定时任务,定时推送那些未接收到ack的消息,保证消息的实时性。
2)拉模式
分为长轮询和短轮询。前端主动询问后端是否有新消息,以定时的频率访问。我们的项目用到了websocket,一般就不用拉模式了,拉模式可以用在历史消息列表获取。因为新消息需要保证及时性,拉模式存在一定的延迟。
3)推拉结合
理论上保证消息的及时性,使用推模式足够了,但是如果推送失败,需要启动定时任务,确保ack,对服务器消耗较大。事实上推送的失败概率没有那么大,如果客户端每隔一段频率进行消息拉取,相当于客户端是定时任务,保证最终的一致性。
1-推送新消息到达时,里面不包含任何特殊信息,只是为了及时出发客户端的消息拉取动作,这个推是无状态的,可以任意调用。可以在先后发送两条消息aa,bb时,aa触发新消息通知,由于网络异常丢失,bb在消息入库时,也会进行消息通知,这时用户拉取新消息时,也会将aa拉取到,这是单纯用消息推送无法实现的点。
2-客户端接收到新消息提醒,或定时任务达到指定时间,对服务端发起拉取新消息的请求,此时带上用户的token即可。
3-服务端查询用户信箱中的未ack消息,全部返回给客户端,从而达到返回增量消息目的。
4-客户端收到消息后,可批量ack,服务端收到ack后,将信箱标记为已读取。
由于整体的流程都变成无状态的请求了。这样客户端在请求新消息的时候,可以请求到批量的消息。客户端在ack的时候,也从原来的一条条ack,变成了可以批量ack。在大群聊很多消息的时候,我们可以通过控制新消息推送的速度,很容易的达到合并拉取的效果。
通过推拉结合的组合,通过无状态通知,减少服务端的压力。由客户端的请求触发最终一致性。收口了核心的接口达到复用效果。但是依然没有解决热点群聊的写扩散问题,所有的消息依然需要写入到用户收信箱。
多端同步
对于多端同步场景,推拉结合就失效了,多端同步的核心是确保消息可靠到达多端。而之前的消息可靠是通过消息ack完成的,对于多端场景,会存在手机端读取到一些消息后,电脑端就读取不到这些消息了,因为手机端已经ack了。
我们可以将多端的状态交给客户端维护,也就是服务端不再维护ack状态。客户端维护该端读取到的最后一条消息的游标,这个游标需要具有唯一性和有序性,可以使用消息id实现。这样每次推送时,都需要对多端进行新消息通知,每次客户端拉取新消息时,客户端不仅需要带上用户的token,还需要带上当前已读到的游标,服务端根据游标,将大于游标的消息全部返回给客户端。
也可以使用收信箱id作为游标来实现,而不是使用消息id,这样对单个用户来说就是实现全局递增了。
单聊群聊
目前市面上的设计都是将消息的类型分为单聊和群聊。单聊的情况下目标id填uid,群聊情况下,目标id填群组id,这样消息虽然兼容了,但后续的收件箱也需要兼容单聊群聊,个人信箱需要个人uid标识,单聊需要加上好友uid,代表会话,群聊加上群组id。但是这样后续其他表只要涉及会话id都需要这两个字段,复用起来比较麻烦。
我们可以抽象出一个房间表,群聊所有人都在一个房间聊天,单聊可以看成两个人在房间聊天,这样房间就能关联上单聊或群聊的相关信息。这样消息表和个人信箱就不需要两个字段标识会话了,直接将房间id作为会话id,通过房间id,就能关联出对应的单聊群聊信息。
可以先抽象出房间表,屏蔽单聊群聊的差异,让其他关心会话的表设计起来更加简单,只需要关联一个房间id即可。
其中单聊表需要唯一确认一个房间,可以通过设计一个room key来唯一标识两个好友的房间。生成规则为uid1_uid2,其中uid1为双方uid较小的,uid2为双方uid较大的。
统计消息已读未读
对于一个万人群聊,每条消息都需要记录所有人的ack,一条消息就需要写入1w条收件箱记录,每人发一条消息,就是1w * 1w=1亿条记录,对存储又很大负担。 我们可以不对用户的收件箱的每条消息都记录ack,只记录用户阅读的最新时间线,类似于在多端同步的时候客户端用到的消息游标。这样用户在ack的时候,后台只需要更新ack的最新时间。这样就不会因为消息而指数扩散了,而只与群成员数有关。这里的已读未读数通过对room_id和read_time进行联合索引计算得到。
消息已被阅读推送
最简单暴力的做法:每个人阅读完消息后,都通知给发送方,然后消息阅读数加1。
但是这种方法的推送频率很高,特别是在万人群聊下,发一条消息,就会收到几千上万的ack推送,并返回几千次的ack给消息发送者。
我们可以优化一些,将已读ack消息推送合并,通过服务端定时任务的方式,将定时任务内的所有ack,合并成一次总的阅读数推送给消息发送者。
也可以使用前端自己查询消息的未读数,只针对当前用户发送的消息进行未读数更新。
热点群聊-读写扩散结合
万人群聊的最大问题是每条消息都需要写入用户收件箱,也就是更新会话表的active_time,这样最新消息的会话才能排序在最前面,否则将排在很后面。
这个更新时间可以不扩散写到用户的收件箱,而是单独写到热点信箱,用户读取的时候综合读取自己收件箱的会话,再合并热点信箱的会话。
也就是说对于小群聊,写扩散到每个用户的收件箱,并更新房间的最新消息游标。
对于热点群聊,直接单独记录该房间的最新游标。
用户在查询自己会话列表的时候,通过聚合层,聚合自己的收件箱,并将所在的热点群聊进行合并排序,最终展示给用户。
这样就能够节省每次热点群聊写扩散的消耗了,实现极致的提升。为了聚合效率更高,可以把热点群聊直接缓存到redis的zset中,这样聚合时速度更快。
精确时间聚合
可以选一张主表用来分页,副表用来聚合。
以用户收件箱为主表,查询第一页,假设查询到3条消息,比如3,5,7,再以3和7作为条件筛选热点群聊中的消息,此时热点群聊中有2,4,18这3条消息,会筛选得到4,而2没有筛选到,此时需要兼容第一页的场景,不应该对start进行限制,只限制end<7,因此筛选出2,3,4,5,7。
查询第二页只有两条,筛选出9和10,以9和10为条件,筛选热点群聊发现筛选不出来消息,此时需要兼容最后一页的场景,不对end进行限制,只限制start>9,聚合得到9,10,18。
精确条数聚合
如果业务要严格要求,希望每一页的条数是固定的,我们可以通过分别对个人收件箱和热点信箱各取一页数据进行候选,再通过归并排序的方式,每次比较普通和热点房间的消息id,取较小的放到结果集合,填满一页即可,在后续页的查询时,可以根据上一页的最后一条记录的游标,确定下一页开始的位置,也就是游标翻页,这是普通翻页无法实现的。这样就能实现每页固定消息条数的情况下,都能够包含普通和热点群聊的消息。
通过对IM系统中可能会出现的问题进行分析,以及对相关场景下可能的解决方案进行对比,选择最适合的方法进行实践。我们的方法可能相比目前市面上成熟的产品有一定的性能差距,但只要是针对具体场景进行分析,选择最优的进行实践也是没问题的。
—END—
参考文献